
In den letzten Kapiteln haben wir einige Aspekte von Perl betrachtet, die nicht unbedingt den Kern der Sprache selbst betreffen, sondern eher sekundärer Natur sind. So haben wir gelernt, wie man mit Hilfe bestimmter Funktionen der Standardbibliothek auf das Dateisystem zugreift, wie man Prozesse erzeugt, wie man Code aus Modulen importiert und mit diesen Modulen die verschiedensten Aufgaben löst oder wie man den Perl-Debugger nutzt. Heute wollen wir, da wir uns inzwischen dem Ende des Buches nähern, wieder dem Kern der Sprache zuwenden und auf die Referenzen zu sprechen kommen. Referenzen stellen eine Möglichkeit dar, indirekt auf andere Daten in Perl zu verweisen. Mit Referenzen kann man Daten oftmals besser und effizienter verwalten, als wenn man die Daten direkt manipulieren würde. In der heutigen Lektion widmen wir uns den folgenden Themen:
Eine Referenz ist eine Form von Daten in Perl, die auf andere Daten verweisen. Die Referenz selbst ist, wie eine Zahl oder ein String, ein Skalar. Man kann sie deshalb wie eine Zahl oder ein String einer Skalarvariablen zuweisen, ausgeben, etwas hinzufügen, auf wahr oder falsch testen, in einer Liste speichern oder einer Subroutine übergeben. Zusätzlich zu diesem skalartypischen Verhalten verweist oder zeigt eine Referenz auf die Position anderer Daten. Um herauszufinden, worauf die Referenz zeigt, dereferenziert man die Referenz - eine etwas hochgestochene Beschreibung dafür, dass man dem Verweis nachgeht, um zu sehen, worauf er verweist.
Falls Sie noch an weiteren terminologischen Pretiosen interessiert sind: das Objekt, auf das die Referenz zeigt, wird auch Referent genannt. Sie dereferenzieren also die Referenz, um den Referenten zu erhalten. Ich persönlich ziehe einfache Formulierungen wie »das Objekt, auf das verwiesen wird« vor.
Referenzen in Perl sind den Zeigern und Referenzen anderer Sprachen sehr ähnlich und bieten die gleichen Vorteile. Wenn Sie jedoch keine anderen Sprachen kennen, könnten Sie sich fragen: »Und wozu das Ganze? Warum sollte man sich mit einer Referenz herumschlagen, wenn man auch mit den Daten selbst arbeiten kann?« Nun, durch den indirekten Bezug auf die Daten können Sie fortschrittlichere Aufgaben mit diesen Daten erledigen - zum Beispiel große Datenmengen als Referenz an oder aus Subroutinen übergeben oder mehrdimensionale Arrays erzeugen. Außerdem eröffnen Referenzen neue fortgeschrittenere Techniken, beispielsweise die Erzeugung objektorientierter Strukturen in Perl. Im Verlauf dieser Lektion werden wir einige dieser Anwendungsmöglichkeiten besprechen.
Bevor ich jetzt zum eigentlichen Code komme, möchte ich noch einen Punkt klarstellen: Wenn ich in diesem Kapitel von Referenzen spreche, so versteht man in versierten Perl-Kreisen darunter die harten Referenzen. In Perl gibt es auch noch eine andere Form der Referenz, die sogenannte symbolische Referenz. So gibt es zwar zweifellos gute Gründe für die Verwendung von symbolischen Referenzen, doch sind harte Referenzen im allgemeinen wesentlich nützlicher, weshalb wir auch den Großteil dieses Kapitels damit füllen. Auf symbolische Referenzen werde ich dann im Vertiefungsabschnitt am Ende dieser Lektion etwas näher eingehen.
Betrachten wir erst einmal einige einfache Beispiele, wie man Referenzen erzeugt und verwendet, damit Sie einen Eindruck von der Technik bekommen. Dabei muss gesagt werden, dass es in Perl mehrere Möglichkeiten gibt, mit Referenzen zu arbeiten. Wir werden uns hier auf die leichtesten und am weitesten verbreiteten Mechanismen konzentrieren und die anderen in einem späteren Abschnitt (»Weitere Möglichkeiten zum Einsatz von Referenzen«) beleuchten.
Beginnen wir mit etwas, womit Sie bereits unzählige Mal in diesem Buch zu tun hatten: eine einfache Skalarvariable, die einen String enthält.
$str = "Dies ist ein String.";
Dies ist eine ganz gewöhnliche Skalarvariable, die ganz gewöhnliche skalare Daten
enthält. Es gibt eine Position im Speicher, die diesen String aufnimmt, an den Sie
über den Variablennamen $str gelangen. Wenn Sie $str etwas anderes zuweisen,
würde die Position im Speicher einen anderen Inhalt bekommen, und $str hätte
einen anderen Wert. All dies ist allgemein bekannt, da Sie es bereits die ganze Zeit so
gemacht haben.
Jetzt möchten wir eine Referenz auf diese Daten erzeugen. Um eine Referenz zu
erzeugen, müssen Sie wissen, wo die fraglichen Daten (ein Skalar, ein Array, ein Hash
oder eine Subroutine) im Speicher abgelegt sind. Um diese Speicherposition zu
erhalten, verwenden Sie den Backslash-Operator (\) und den Variablennamen:
$strref = \$str;
Der Backslash-Operator ermittelt die Speicherposition der Daten, die in $str
gespeichert sind, und erzeugt eine Referenz auf diese Position. Diese Referenz wird
dann der Skalarvariablen $strref zugewiesen (zur Erinnerung: Referenzen sind eine
Art von skalaren Daten).
Der Backslash-Operator ist dem Adreßoperator (
&) von C sehr ähnlich. Beide werden verwendet, um auf die Speicherposition von Daten zuzugreifen.
Zu keiner Zeit kommt der eigentliche Inhalt von $str - der String »Dies ist ein String«
ins Spiel. Die Referenz beschäftigt sich nicht mit dem Inhalt von $str, sondern nur
mit seiner Position. Außerdem bleibt $str eine Skalarvariable, die einen String
enthält. Die Existenz einer Referenz ändert daran nichts (siehe Abbildung 19.1).
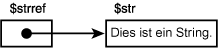
Abbildung 19.1: Eine Variable, ein String und eine Referenz
Dieses Beispiel erzeugt eine Referenz auf einen String. Sie können jedoch auch Referenzen auf Arrays, Hashes oder Subroutinen erzeugen - sozusagen auf alles, was eine Speicherposition in Perl hat. Sehen Sie im folgenden das Beispiel für eine Referenz auf ein Array:
@array = (1..10);
$arrayref = \@array;
Und hier ist ein Beispiel für einen Hash:
%hash = (
'rot' => '0 0 255',
'gruen' => '0 255 0',
'blau' => '255 0 0; );
$hashref = \%hash;
Wie schon bei der Referenz auf einen skalaren Wert bleiben das Array und der Hash
in diesen Beispielen Arrays und Hashes, die in den Variablen @array und %hash
gespeichert sind. Und die Array- und Hash-Referenzen in $arrayref und $hashref
sind skalare Daten, unabhängig von den Daten, auf die sie zeigen. Das Wichtigste,
was Sie sich hiervon merken sollten, ist die Tatsache, dass die Referenz selbst ein
Skalar ist. Das, worauf die Referenz verweist, kann praktisch jede Art von Daten sein.
Sie können auch Referenzen auf Subroutinen erzeugen. Da dies jedoch ein eher fortgeschrittenes Thema ist und nicht so oft zur Anwendung kommt wie Referenzen auf Skalare, Arrays und Hashes, werde ich Referenzen auf Subroutinen und deren Einsatz erst im Vertiefungsabschnitt am Ende dieser Lektion beschreiben.
Sie haben inzwischen mit Hilfe des Backslash-Operators eine Referenz erzeugt und in einer Skalarvariablen gespeichert. Wie sehen diese Referenzen aus? Sie sind Skalare und können deshalb auch überall dort verwendet werden, wo Skalare erlaubt sind. Und wie bei Zahlen oder Strings ist ihr Verhalten kontextabhängig.
Wenn Sie eine Referenz als String verwenden, enthält der String die Information, auf welche Art von Daten die Referenz verweist (ein Skalar, ein Array, ein Hash und so weiter), und eine Hexadezimalzahl, die die interne Speicherposition angibt, auf die die Referenz zeigt. Wenn Sie also folgenden Code hätten:
print "$strref\n";
sähe die Ausgabe ungefähr folgendermaßen aus:
SCALAR(0x807f61c)
Die Ausgaben für $arrayref und $hashref wären entsprechend:
ARRAY(0x807f664)
HASH(0x807f645)
Wenn Sie eine Referenz in einem numerischen Kontext verwenden, erhalten Sie die gleiche Hexadezimalzahl wie bei Verwendung der Referenz in einem String-Kontext - eine Zahl, die die Speicherposition darstellt, auf die die Referenz zeigt. Die Zahlen, die sowohl in der String- als auch der Zahlendarstellungen der Referenz auftauchen, variieren in Abhängigkeit davon, wann das Skript ausgeführt wird und welcher Speicher gerade für Perl frei ist. Sie sollten sich nicht auf diese Zahlen verlassen; betrachten Sie sie lediglich als eine interne Darstellung des Ortes, auf den die Referenz zeigt.
Weitere Anwendungen von Referenzen? Sie können Referenzen Skalarvariablen zuweisen (wie in unserem Beispiel), sie als Listenelemente verwenden oder sie in Arrays oder Hashes speichern (Sie können sie jedoch nicht als Hash-Schlüssel verwenden - mehr dazu später). Eine Referenz, die als Test verwendet wird, liefert immer wahr zurück. Die mit Abstand gebräuchlichste Art, eine Referenz zu nutzen, besteht allerdings darin, sie zu dereferenzieren, um dadurch Zugriff auf die Daten zu erhalten, auf die die Referenz zeigt.
Wenn Sie eine Referenz dereferenzieren, greifen Sie auf die Daten zu, auf die die Referenz zeigt. Sie können sich auch vorstellen, dass Sie der Referenz folgen oder auf die Position, auf die sich die Referenz bezieht, zugreifen. Genau dies bezeichnet man allgemein mit dem Begriff dereferenzieren.
Es gibt mehrere Möglichkeiten, eine Referenz zu dereferenzieren. Der einfachste Weg besteht darin, die Skalarvariable der Referenz dort einzusetzen, wo sonst ein einfacher Variablenname erwartet würde:
$originalstr = $$strref;
Zwei Dollarzeichen? Ja, denn ein einfaches Dollarzeichen markiert lediglich die
Skalarvariable $strref, die Ihnen die Referenz selbst liefert. Das zweite Dollarzeichen
besagt: »Gib mir das, worauf $strref zeigt.« In diesem Fall wäre das, worauf $strref
verweist, der Originalstring »Dies ist ein String«. Sie können sich die zwei
Dollarzeichen auch so erklären, dass Sie den Namen der Variablen, auf die Sie
zugreifen wollen, durch die Referenz - $strref - ersetzen.
Um einer Array-Referenz zu folgen und Zugriff auf das Array selbst zu erhalten, gehen
Sie genau gleich vor, allerdings mit einem @-Zeichen, und $arrayref steht dort, wo
der Name des Arrays stehen würde:
@ersteliste = @$arrayref;
Der Inhalt von @ersteliste ist jetzt das ursprüngliche Array, das wir erzeugt haben
und auf das $arrayref gezeigt hat (genau genommen ist es eine Kopie der ganzen
Elemente dieses Arrays).
Sie möchten über eine Referenz auf ein Array-Element zugreifen? Kein Problem. Die Regel ist die gleiche: Setzen Sie einfach die Variable, die die Referenz enthält, dorthin, wo der Name des Array stehen müßte:
$erstes = $$arrayref[0];
Und mit der gleichen Regel erhalten Sie auch die oberste Indexzahl eines Arrays:
$index = $#$arrayref;
Bei Hashes ist das nicht anders:
%neueshash = %$hashref; # das kopieren, worauf $hashref zeigt
$wert = $$hashref{rot}; # ermittelt den Wert für den Schlüssel "rot"
@keys = keys %$hashref; # extrahiert die Schlüssel
Kommen wir jetzt zum schwierigen Teil: das Ändern der Daten, auf die die Referenz
verweist. Angenommen Sie haben wie in den obigen Beispielen eine Referenz
$strref. Nun wird aber der Wert von $str geändert:
$str = "Dies ist ein String."
$strref = \$str;
#...
$str = "Dies ist ein anderer String."
Was passiert mit der Referenz $strref? Sie bleibt weiter bestehen. Sie zeigt weiterhin
auf die Speicherposition der Variablen namens $str. Wenn Sie sie dereferenzieren,
erhalten Sie den neuen String:
print "$$strref\n"; # Ausgabe: " Dies ist ein anderer String."
Die Referenz selber schert sich nicht um den Inhalt des Speicherplatzes, auf den sie verweist, sondern nur um die Speicherposition. Sie können den Inhalt also beliebig ändern - die Referenz wird immer auf die gleiche Position zeigen. Jedesmal, wenn Sie die Referenz dereferenzieren, erhalten Sie das, was gerade zur Zeit an dieser Position im Speicher steht.
Beachten Sie, dass sich dies von der Zuweisung regulärer Variablen unterscheidet, denn dort wird der Inhalt einer Speicherposition an eine andere Position kopiert. Referenzen zeigen immer auf die gleiche Speicherposition, und der Inhalt kann ohne Beeinflussung der Referenz geändert werden. Nehmen Sie zum Beispiel folgende Anweisungen:
@array1 = qw(Achtung Fertig Los);
@array2 = @array1;
$arrayref = \@array1;
push @array1, "Stop";
$, = ' '; # setzt den Begrenzer für die Array-Elemente
print "@array1\n";
print "@array2\n";
print "@$arrayref\n";
Können Sie erraten, was für jede der drei print-Anweisungen ausgegeben wird? Der
Inhalt von @array1 wird in der ersten Anweisung erzeugt und später in der vierten
geändert, so dass die Ausgabe von @array1 folgendermaßen lautet:
Achtung Fertig Los Stop
@array2 wird in Zeile 2 der Inhalt von @array1 zugewiesen. Durch die
Listenzuweisung wird das rechte Array in seine Bestandteile erweitert, und dann
werden diese Bestandteile dem Array auf der linken Seite zugewiesen. So erhält
@array2 eine Kopie des aktuellen Inhalts von @array1. Wird @array2 ausgegeben,
erzeugt es folgende Ausgabe:
Achtung Fertig Los
Die Änderungen an @array2 haben keine Auswirkungen auf @array1. Beides sind
getrennte Arrays mit voneinander unabhängigen Inhalten.
Die Referenz auf @array1 in $arrayref wird jedoch die gleiche Ausgabe liefern wie
der aktuelle Inhalt von @array1, da die Referenz auf die gleiche Speicherposition zeigt
wie @array1. Die Ausgabe dieser Dereferenzierung lautet daher:
Achtung Fertig Los Stop
Inzwischen dürften Sie eine Vorstellung davon haben, wie Referenzen funktionieren. Es gäbe noch eine Menge zum Erzeugen und Verwenden von Referenzen zu sagen, aber lassen Sie uns hier erst einmal pausieren und uns der Praxis zuwenden. Im Kapitel 11, »Subroutinen erzeugen und verwenden«, habe ich im Zusammenhang mit den Subroutinen erwähnt, dass Listen und Subroutinen dazu neigen, unhandlich zu werden, wenn man keine Referenzen verwendet. Ich möchte nun auf dieses Thema zurückkommen und untersuchen, wie man mit Referenzen die Listenargumente und Rückgabewerte von Subroutinen wesentlich einfacher verwalten kann.
Wie Sie bereits wissen, verfügt Perl nur über ganz elementare Möglichkeiten zur
Übergabe und zur Rückgabe von Argumente an und aus Subroutinen. Alle
Listenargumente, die an eine Subroutine übergeben werden, werden in einer einzigen
Liste zusammengefaßt und in @_ gespeichert. Rückgabewerte werden ebenfalls als
einfacher Skalar oder als eine einfache Liste von Skalaren zurückgegeben. Die
einfachen Argumente lassen sich dadurch zwar leicht bearbeiten, doch gilt dies nicht
für Subroutinen, die mehrere Listen als Argumente übernehmen, da diese Listen auf
ihrem Weg in die Subroutine ihre Identität verlieren. Wie ich bereits in Kapitel 11
angemerkt habe, können Sie diese Beschränkung auf vielfältige Weise umgehen. So
können Sie zum Beispiel Listen in globalen Array- oder Hash-Variablen speichern
(und damit die Übergabe von Argumenten überhaupt vermeiden) oder Informationen
über die Listen selbst als Argument übergeben (wie die Länge), was Ihnen dann hilft,
die Liste innerhalb der Subroutine selbst zu rekonstruieren.
Am geschicktesten - und oft auch am effizientesten - umgehen Sie Perls Hang, Listenargumente an Subroutinen zu einer Liste zusammenzufassen, indem Sie es überhaupt vermeiden, Listeninhalte an Subroutinen zu übergeben. Übergeben Sie statt dessen Referenzen, und dereferenzieren Sie diese Referenzen dann innerhalb der Subroutine, um an die Inhalte der Listen zu gelangen.
Betrachten wir ein Beispiel, das aus einer früheren Übung stammt: eine Subroutine,
die zwei Arrays als Argumente übernimmt und eine Liste aller Elemente zurückliefert,
die beiden gemeinsam sind (die Schnittmenge der beiden Arrays). Die Länge des
ersten Arrays wird als erstes Argument übergeben, so dass wir die beiden Arrays
innerhalb der Subroutine rekonstruieren können. Im folgenden Beispiel rufen wir
dafür die Funktion splice auf (denken Sie daran, dass shift ohne Argumente
innerhalb einer Subroutine @_ verschiebt):
1: sub inter {
2: my @first = splice(@_,0,shift);
3: my @final = ();
4: my ($el, $el2);
5:
6: foreach $el (@first) {
7: foreach $el2 (@_) {
8: if (defined $el2 && $el eq $el2) {
9: push @final,$el2;
10: undef $el2;
11: last;
12: }
13: }
14: }
15: return @final;
16: }
Wir rufen diese Subroutine mit einer Längenangabe und zwei Arrays als Argumente auf:
@one = (1..10);
@two = (8..15);
@three = inter(scalar(@one),@one,@two);
Man könnte jetzt behaupten, dass dieses Beispiel gar nicht so schrecklich ist. Es sind
schließlich nur zwei Arrays, und mit splice wird dafür Sorge getragen, dass die
Elemente korrekt getrennt werden. Was aber, wenn Sie mehr als zwei Arrays als
Argumente hätten? Da hätten Sie viel zu trennen. Und wenn dann noch eines der
Arrays extrem groß wäre, müßten Sie erst einmal eine Menge Elemente kopieren,
bevor Sie damit beginnen könnten, tatsächlich irgendwelche Elemente zu verarbeiten.
Nicht gerade sehr effizient.
Wagen wir uns jetzt an eine Neufassung dieser Subroutine, die Referenzen verwendet. Anstatt der Subroutine die eigentlichen Arrays zu übergeben, übergeben wir Referenzen auf diese Arrays. Innerhalb der Subroutine weisen wir diese Referenzen dann Variablen zu und dereferenzieren sie, um den Inhalt zu erhalten. Unsere neue Subroutine könnte folgendermaßen aussehen:
1: sub inter {
2: my ($first, $second) = @_;
3: my @final = ();
4: my ($el, $el2);
5:
6: foreach $el (@$first) {
7: foreach $el2 (@$second) {
8: if (defined $el2 && $el eq $el2) {
9: push @final,$el2;
10: undef $el2;
11: last;
12: }
13: }
14: }
15: return @final;
16: }
Diese Subroutine rufen wir nur mit zwei Argumenten auf: den Referenzen auf die Arrays:
@one = (1..10);
$oneref = \@one;
@two = (8..14);
$tworef = \@two;
@three = inter($oneref,$tworef);
Es gibt nur zwei Unterschiede zwischen dieser Subroutine und der vorherigen: die
erste Zeile für die Argumentliste (Zeile 2) und die Referenzen auf die Listen in den
beiden verschachtelten foreach-Schleifen (Zeilen 6 und 7). In der Referenzversion
brauchen wir die Elemente der Argumentliste nicht mit splice zu trennen. Die
Argumentliste enthält nur zwei Elemente: die zwei skalaren Referenzen. Deshalb
können wir splice durch eine gewöhnliche Skalarzuweisung an zwei lokale Variablen
ersetzen.
Mit diesen Referenzen kommen wir zu den foreach-Schleifen, die die einzelnen
Listenelemente überprüfen. Hier arbeiten wir nicht mehr mit lokalen Arrays, sondern
nur noch mit Referenzen. Um an den Inhalt der Arrays zu gelangen, dereferenzieren
wir die Referenzen mit @$first und @$second und greifen auf diese Weise auf den
Inhalt der Arrays zu.
Bei dieser Subroutine behält jedes Array seinen ursprünglichen Inhalt und Aufbau. Wenn Sie Referenzen auf Hashes übergeben, bleiben diese Hashes und werden nicht in Listen zusammengefaßt. Außerdem entfällt das lästige Kopieren der Listendaten von einem Ort zu einem anderen, wie das bei der Übergabe von regulären Listen erforderlich ist. Diese Vorgehensweise ist wesentlich effizienter und oftmals auch leichter durchzuführen und zu verstehen, vor allem bei Subroutinen mit komplexen Argumenten.
Das Gegenstück zum Übergeben von Listen an Subroutinen ist das Zurückgeben von
Listen aus Subroutinen mittels des return-Operators. Standardmäßig liefert return
entweder einen einfachen Skalar oder eine Liste zurück, wobei mehrere Listen in
einer Liste zusammengefaßt werden.
Um mehrere Elemente aus einer Subroutine zurückzugeben und dabei die Integrität von Listen und Hashes zu wahren, liefern Sie einfach Referenzen auf diese Strukturen zurück. Gehen Sie dabei genauso vor wie bei der Übergabe von Listendaten an eine Subroutine:
sub foo {
my @templist;
my @temphash;
#...
my $tempref = \@templist;
my $temphashref = \@temphash;
return ($tempref, $temphashref);
}
Dies mag auf den ersten Blick wie ein Fehler erscheinen, denn die Variablen in diesem
Beispiel, @templist und %temphash, sind lokale Variablen, die aufgelöst werden,
nachdem die Subroutine ausgeführt worden ist. Wenn aber die Variablen ihren
Gültigkeitsbereich verlieren, stellt sich die Frage, worauf die Referenzen überhaupt
noch verweisen? Das Geheimnis hierbei ist, dass zwar der Variablenname
verschwindet, wenn die Variable ihren Gültigkeitsbereich verliert (das heißt, wenn die
Ausführung der Subroutine beendet ist), dass aber die Daten noch existieren und die
Referenz auch noch weiterhin darauf zeigt. Genau genommen ist die
Dereferenzierung dieser Referenz jetzt der einzige Weg, um weiterhin Zugriff auf
diese Daten zu haben. Dieses Verhalten beeinflußt auch die Art und Weise, wie Perl
Speicher belegt und freigibt, während Ihr Skript ausgeführt wird. Doch zu diesem
Thema mehr im Abschnitt »Einige Anmerkungen zu Speicher und
Speicherbereinigung«.
Meist erzeugt man Referenzen mit Hilfe des Backslash-Operators und dereferenziert sie, indem man die Referenz dort einsetzt, wo an sich ein Name erwartet wird. Doch gibt es noch viele weitere Wege, Referenzen zu erzeugen und nutzen, von denen Ihnen einige neue und komplexe Möglichkeiten eröffnen und anderes in besser lesbarer Form bewirken. In diesem Abschnitt möchte ich Ihnen einige dieser Wege zum Erzeugen und Nutzen von Referenzen aufzeigen und einige weitere Themen rund um Referenzen ansprechen.
Angenommen Sie haben eine Referenz auf eine Liste. Dann werden Sie diese Referenz wahrscheinlich am häufigsten dazu nutzen, Zugriff auf die einzelnen Elemente in der Liste zu erhalten - um sie auszugeben, zu sortieren, aufzuteilen und so weiter. Das könnten Sie zum einen mit der Syntax machen, die wir zu Beginn dieser Lektion gelernt und im vorigen Beispiel verwendet haben:
print "Kleinste Zahl: $$ref[0]\n";
Diese spezielle Zeile gibt das erste Element des Arrays aus, auf das die Referenz $ref
zeigt. Wenn Sie das gleiche bei einem Hash machen wollten, müßten Sie die Hash-
Syntax verwenden und den Hash-Namen durch die Referenz ersetzen:
print "Johns Nachname: $$ref{john}\n";
Es gibt jedoch noch einen anderen Weg, Zugriff auf die referenzierten Listen- und
Hash-Elemente zu erhalten - ein Weg, der in vielen Fällen (besonders bei komplexen
Datenstrukturen und objektorientierten Objekten) etwas einfacher zu lesen ist.
Verwenden Sie die Referenz, den Pfeiloperator (->) und einen Array-Index, um auf die
referenzierten Listenelemente zuzugreifen:
$erstes = $listref->[0];
Beachten Sie, dass in diesem Ausdruck nur ein Dollarzeichen steht. Dieser Ausdruck
dereferenziert die Listenreferenz in der Variablen $listref und liefert das 0-te
Element der Liste zurück. Damit entspricht dieser Ausdruck exakt dem
Standardmechanismus zum Dereferenzieren:
$erstes = $$listref[0];
Diese Syntax läßt sich auch auf Hashes übertragen; verwenden Sie in diesem Fall die
Hash-Referenz, den Pfeiloperator (->) und den Hash-Schlüssel in Klammern:
$wert = $hashref->{$key};
Diese Form ist identisch mit folgendem Ausdruck:
$wert = $$hashref{$key};
Verwechseln Sie den Pfeiloperator
->nicht mit dem Hash-Paar-Operator=>. Ersterer wird verwendet, um eine Referenz zu dereferenzieren, letzterer ist das gleiche wie ein Komma und wird verwendet, um die Syntax für die Initialisierung von Hash-Inhalten besser lesbar zu machen.
Wir werden auf diese Syntax noch einmal im Abschnitt »Verschachtelte Datenstrukturen mit Referenzen« zu sprechen kommen.
Ein dritter Weg, Referenzen zu dereferenzieren, ist dem ersten Weg recht ähnlich. Anstatt jedoch den Namen der Referenzvariable an die Stelle eines regulären Variablennamens zu setzen, ersetzen Sie diesen durch einen Block (geschweifte Klammern), der bei seiner Auswertung eine Referenz zurückliefert. Angenommen Sie hätten zum Beispiel eine Referenz auf eine Liste:
$listref = \@list;
Mit normaler Dereferenzierung würden Sie auf das dritte Element in der Liste wie folgt zugreifen:
$third = $$listref[3];
$third = $listref->[3];
$third = ${$listref}[3];
Um an den Inhalt oder den letzten Index einer Liste über eine Referenz zu gelangen, können Sie wie gewohnt schreiben:
@list = @$listref;
$index = $#$listref;
@list = @{$listref};
$index = $#{$listref};
Die obigen Blöcke sind nicht gerade besonders sinnvolle Beispiele in Anbetracht der
Tatsache, dass sie lediglich die Variable $listref auswerten und Sie dies fast genauso
leicht und mit weniger Zeichen durch eine ganz gewöhnliche Dereferenzierung
erreichen könnten. Sie könnten jedoch in dem Block selbst eine Subroutine aufrufen,
die dann eine Referenz zurückliefert, Sie könnten eine if-Bedingung verwenden, um
zwischen Referenzen zu wählen, oder im Block einen weiteren Ausdruck aufnehmen.
Es muss ja nicht immer nur eine einfache Variable sein.
Mit Hilfe der Blockdereferenzierung können Sie komplexe Dereferenzierungen für komplexe Strukturen, die diese Referenzen verwenden, ausführen. Dieses Thema werden wir noch ausführlicher im Abschnitt »Zugriff auf Elemente in verschachtelten Datenstrukturen« behandeln.
Angenommen Sie haben eine Referenz in einer Skalarvariablen gespeichert und
möchten jetzt wissen, welcher Art die Daten sind, auf die die Referenz verweist, damit
Sie nicht plötzlich versuchen, Listen zu multiplizieren oder Elemente aus einem String
auszulesen. Dafür gibt es in Perl eine vordefinierte Funktion namens ref.
Die ref-Funktion übernimmte einen Skalar als Argument. Ist der Skalar keine
Referenz, das heißt, ist er ein String oder eine Zahl, dann liefert ref einen Null-String
zurück. Andernfalls liefert er einen String zurück, der angibt, welcher Art die
referenzierten Daten sind. In Tabelle 19.1 finden Sie die möglichen Werte.
Im Vertiefungsabschnitt werden wir Referenzen auf Subroutinen und Typeglobs besprechen.
Die ref-Funktion wird meist dazu verwendet, den Typ einer Referenz zu ermitteln:
if (ref($ref) eq "ARRAY") {
foreach $key (@$ref) {
#...
}
} elsif (ref($ref eq "HASH") {
foreach $key (keys %$ref) {
#...
}
}
Einer der Nebeneffekte beim Verwenden von Referenzen betrifft die Menge an Speicherplatz, die Perl besetzt, wenn es Ihr Skript ausführt und verschiedene Arten von Daten erzeugt. Normalerweise reserviert Perl bei der Ausführung Ihres Skripts automatisch Speicherbereiche für Ihre Daten und fordert diese Bereiche wieder zurück, wenn Sie fertig sind. Der Prozeß der Rückforderung - auch Speicherbereinigung genannt - unterscheidet Perl von vielen anderen Sprachen wie zum Beispiel C, wo Sie selbst Speicher allokieren und freigeben müssen.
Perl verwendet etwas, was man einen Referenzen zählenden Speicherbereiniger nennt. Das bedeutet, dass Perl für alle Daten verfolgt, wie viele Referenzen - einschließlich des ursprünglichen Variablennamens - auf die Daten verweisen. Wenn Sie also eine Referenz auf bestimmte Daten erzeugen, inkrementiert Perl die Referenzzählung um 1. Wenn Sie die Referenz auf etwas anderes verschieben oder eine lokale Variable, die Daten enthält, am Ende eines Blocks oder einer Subroutine verschwindet, dekrementiert Perl die Referenzzählung. Und liegt die Referenzzählung bei 0 - das heißt, es gibt keine Variablen, die sich auf diese Daten beziehen, noch irgendwelche Referenzen, die auf die Daten verweisen -, fordert Perl den Speicherbereich, der von den Daten eingenommen wurde, wieder zurück.
In der Regel läuft dies alles automatisch ab, und Sie müssen sich in Ihrem Skript um gar nichts kümmern. Es gibt jedoch in Zusammenhang mit den Referenzen einen Fall, bei dem Sie vorsichtig sein müssen: wenn es zu Kreisschlüssen durch Referenzen kommt.
Betrachten wir die folgenden zwei Referenzen:
sub silly {
my ($ref1, $ref2);
$ref1 = \$ref2;
$ref2 = \$ref1;
# .. törichte Dinge!
}
In diesem Beispiel zeigt die Referenz in $ref1 auf das, worauf auch $ref2 zeigt, und
$ref2 zeigt auf das, worauf auch $ref1 zeigt. Dieses Phänomen nennt man einen
Kreisschluß. Die Schwierigkeit dabei ist, dass die lokalen Variablennamen $ref1 und
$ref2 zwar verschwinden, wenn die Subroutine ihre Ausführung beendet hat, die in
den lokalen Variablen enthaltenen Daten aber weiterhin zumindest einmal referenziert
werden, so dass der Speicher für diese Referenzen nicht zurückgefordert werden
kann. Und ohne die Variablennamen oder eine zurückgelieferte Referenz auf die eine
oder andere Referenz können Sie nicht einmal auf die Daten aus der Subroutine
zugreifen. Die Daten liegen dann einfach so im Speicher herum. Und jedesmal, wenn
die Subroutine bei Ausführung Ihres Skripts aufgerufen wird, wächst der
Speicherbereich, den Sie nicht mehr zurückfordern können, an, bis Perl irgendwann
den ganzen Speicher auf Ihrem System belegt hat, wenn Ihr Skript nicht vorher die
Ausführung abbricht.
Kreisschlüsse durch Referenzen sind demnach schädlich. Und sollte Ihnen dieses
Beispiel hier etwas dumm und zu leicht zu durchschauen erscheinen, so möchte ich
Sie darauf hinweisen, dass man bei komplexen Datenstrukturen, bei denen überall
Referenzen irgendwo hinzeigen, durchaus Gefahr läuft, zufällig und unbeabsichtigt
eine Kreisreferenz zu erzeugen. Denken Sie also daran, alle Referenzen, die Sie in
Blöcken oder Subroutinen verwenden, »aufzuräumen« (verwenden Sie undef, oder
weisen Sie ihnen eine 0 oder '' zu), um sicherzustellen, dass der Speicher immer
wieder zurückgefordert wird.
Doch Referenzen sind nicht nur in Subroutinen nützlich. Sie dienen noch einem anderen wichtigen Zweck. Ohne sie gäbe es keine komplexen Datenstrukturen wie zum Beispiel mehrdimensionale Arrays. In diesem Abschnitt möchte ich Ihnen zeigen, wie man komplexe Datenstrukturen mit verschachtelten Arrays und Hashes auf der Basis von Referenzen und anonymen Daten aufbaut. Weiter hinten in dieser Lektion, im Abschnitt »Zugriff auf Elemente in verschachtelten Datenstrukturen«, erfahren Sie dann, wie Sie die Daten wieder aus den verschachtelten Datenstrukturen, die Sie gerade erzeugt haben, auslesen.
Normalerweise sind Listen, Arrays und Hashes in Perl flach und eindimensional und enthalten nichts außer Skalare. Wenn Sie mehrere Listen kombinieren, werden diese alle in einer Liste zusammengefaßt. Hashes sind im Grunde genommen das gleiche wie Listen, bei denen nur die Daten intern anders organisiert sind. Dadurch wird zwar das Erzeugen und Verwenden von Datensammlungen recht einfach, wenn Sie jedoch versuchen, größere oder komplexere Datensätze effizient zu repräsentieren, stoßen Sie bald an die Grenzen dieses Konzepts.
Angenommen Ihre Daten bestehen aus Informationen über Menschen: Vorname, Nachname, Alter, Größe und Namen der Kinder. Wie würden Sie diese Daten darstellen? Vor- und Nachname sind kein Problem: Sie erzeugen einen Hash mit dem Nachnamen als Schlüssel und weisen diesem Schlüssel dann die Vornamen als Werte zu. Jetzt die Größe - nun gut, Sie könnten für die Größen einen zweiten Hash erzeugen, der ebenfalls den Nachnamen als Schlüssel verwendet. Doch was machen Sie, wenn Sie die Namen der Kinder aufnehmen wollen? Vielleicht einen dritten Hash einrichten, der ebenfalls den Nachnamen als Schlüssel nutzt und dessen Werte Strings sind, die die durch Doppelpunkte getrennten Namen der Kinder enthalten und bei Bedarf wieder in die einzelnen Namen zerlegt werden? Sie sehen: Sobald die Daten komplex werden, versinkt man in einem Wust einfacher Listen, oder man erzeugt seltsame Gebilde mit Strings, weil man ansonsten keine Listen innerhalb von anderen Listen speichern kann.
Hier kommen nun die Referenzen ins Spiel. Eine Liste ist eine flache Sammlung von Skalaren - daran ändert sich auch nach Einführung der Referenzen nichts. Aber eine Referenz ist ein Skalar - und eine Referenz kann auf eine andere Liste verweisen. Und diese Liste kann selbst auch wieder Referenzen auf andere Listen enthalten. Kapiert? Mit Referenzen können Sie Listen in Listen, Arrays in Arrays und Hashes in Arrays verschachteln, aber auch Arrays als Werte für Hashes verwenden und so weiter. All diese Konstrukte - eine beliebige Kombination von Listen, Arrays und Hashes - nennen wir verschachtelte Datenstrukturen.
Auch wenn Referenzen für das Erzeugen von verschachtelten Datenstrukturen unentbehrlich sind, sind sie nicht das einzige Hilfsmittel, das das Erstellen von verschachtelten Datenstrukturen leichter macht. Neben den Referenzen sollte man sich auch mit anonymen Daten auskennen. Der Begriff anonym bedeutet »ohne einen Namen«. Anonyme Daten beziehen sich speziell in Perl auf Daten (normalerweise Arrays oder Hashes, aber auch Subroutinen), auf die nur über eine Referenz zugegriffen werden kann - also Daten, die mit keinem Variablennamen verbundenen sind.
Wie schon im letzten Abschnitt betrachten wir auch hier vornehmlich Arrays und Hashes. Anonyme Subroutinen und die Referenzen werde ich im Vertiefungsabschnitt am Ende dieser Lektion ansprechen.
Anonymen Daten sind wir schon weiter vorne in diesem Kapitel begegnet, als wir Arrays in Subroutinen erzeugt und dann Referenzen auf diese Arrays zurückgeliefert haben. Nachdem die Subroutine abgelaufen ist, verschwindet die ursprüngliche lokale Variable, die die Daten enthält, und der einzige Weg, auf die Daten zuzugreifen, führt über eine Referenz. Diese Daten nennt man dann anonym.
Anonyme Daten sind für verschachtelte Datenstrukturen nützlich, weil Sie für die Erzeugung einer Liste von Listen dann nur einen einzigen Variablennamen für die äußere Liste benötigen (und selbst auf diesen könnte man verzichten). Sie brauchen keine einzelnen Variablen für alle Daten innerhalb der Liste, Referenzen reichen völlig aus.
Sie könnten die anonymen Daten für Ihre verschachtelten Datenstrukturen mit Hilfe
lokaler Variablen von Subroutinen oder Blöcken erzeugen. In einigen Situationen,
beispielsweise wenn Sie Strukturen mit Daten füllen, die Sie aus Dateien oder der
Standardeingabe einlesen, ist dies sogar meist der einfachste Weg. Es gibt aber noch
eine andere Möglichkeit, anonyme Daten zu erzeugen, und zwar mit Hilfe einer
speziellen Perl-Syntax: eckige Klammern [] oder geschweifte Klammern {}.
Angenommen Sie wollten eine Referenz auf ein Array erzeugen. Normalerweise würden Sie dazu wie folgt vorgehen:
@array = ( 1..10 );
$arrayref = \@array;
Doch daran ist nichts anonym. Das Array wird in der Variablen @array gespeichert.
Um das gleiche Array anonym zu erzeugen, müssen Sie die Liste in eckigen
Klammern statt in runden Klammern initialisieren. Das Ergebnis wäre eine Referenz,
die Sie dann speichern können:
$listref = [ 1..10 ];
Auf dieses Array kann über die Referenz zugegriffen werden. Sie können die Referenz genauso wie für jedes andere Array dereferenzieren. Aber Sie können nicht über einen Variablennamen auf das Array zugreifen - es handelt sich um anonyme Daten.
Mit anonymen Hashes können Sie genauso verfahren. Hier erzeugen die geschweiften Klammern eine Referenz auf einen anonymen Hash:
$hashref = {
'Taylor' => 12,
'Ashley' => 11,
'Jason' => 12.
'Brendan' => 13,
}
Beachten Sie, dass die Elemente in dem Hash weiterhin als Paare vorliegen - eine Kombination aus Schlüssel und Werten, wie bei normalen Hashes.
Die hier verwendeten eckigen und geschweiften Klammern sollten nicht mit denen verwechselt werden, die bei den Array-Indizes
$array[0]und den Hash-Zugriffen$hash{key}zum Einsatz kommen. Die Zeichen sind die gleichen, so dass man sich leichter merken kann, dass eckige Klammern zu den Arrays gehören und geschweifte Klammern zu den Hashes. Aber die Funktion der Klammern ist eine völlig andere.
Array- und Hash-Klammern konstruieren ein Array oder ein Hash im Speicher und liefern dann eine Referenz auf diese Speicherposition zurück. Alles, was Sie in einem Array oder einem Hash ablegen können, können Sie auch in anonyme Array- oder Hash-Klammern setzen. Dazu gehören auch Array- und Hash-Variablen, obwohl die folgenden zwei Zeilen nicht das gleiche Ergebnis liefern:
$arrayref = \@array;
$arrayref = [ @array ];
Der Unterschied zwischen diesen zwei Zeilen ist der, dass die erste Referenz auf die
eigentliche Speicherposition der Variablen @array zeigt, während die zweite ein neues
Array anlegt, in dem alle Elemente von @array kopiert werden, und dann eine
Referenz auf diese neue Speicherposition erzeugt. Sie könnten es auch als die
Erzeugung einer Referenz auf eine Kopie von @array bezeichnen. Diesen Trick sollten
Sie sich unbedingt für später merken, wenn wir Datenstrukturen in Schleifen
erzeugen.
Mit anonymen Daten und Referenzen ist das Erstellen von verschachtelten Datenstrukturen letztlich nur eine Frage des Zusammenfügens. In diesem Abschnitt untersuchen wir drei verschiedene Arten von verschachtelten Datenstrukturen: Arrays von Arrays, Hashes von Arrays und Hashes von Hashes.
Beginnen wir mit etwas einfachem: einem Array von Arrays oder auch einem mehrdimensionalen Array (siehe Abbildung 0.2). Sie könnten zum Beispiel ein Array von Arrays verwenden, um eine Art von zweidimensionalem Feld (wie ein Schachbrett) zu erzeugen. Dabei hat jedes Feld auf dem »Brett« eine Position irgendwo in einer Reihe, und die Reihen werden in dem größeren Array gespeichert.
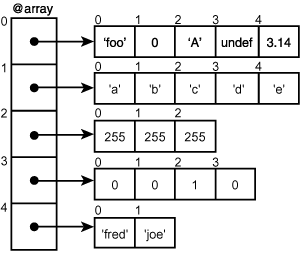
Abbildung 19.2: Ein Array von Arrays
Wenn Sie von C her an echte mehrdimensionale Arrays gewöhnt sind, sollten Sie sich vergegenwärtigen, dass die mehrdimensionalen Arrays in Perl eher Arrays von Zeigern sind und nicht im eigentlichen Sinne mehrdimensional.
Um ein Array von Arrays zu erzeugen, verwendet man für die inneren Arrays die Syntax der anonymen Arrays und für das äußere Array die reguläre Listensyntax. Das folgende Array von Arrays enthält die RGB-Werte für verschiedene Schattierungen von Grau.
@grauwerte = (
[ 0, 0, 0 ],
[ 63, 63, 63 ],
[ 127, 127, 127 ],
[ 191, 191, 191 ],
[ 255, 255, 255],
);
Hier stehen die Arrays mit den Zahlen in eckigen Klammern, wodurch Referenzen auf diese Arrays erzeugt werden. Dann erzeugt das größere Array innerhalb der runden Klammern ein einfaches Array dieser Referenzen. Hüten Sie sich vor folgendem Fehler:
@grauwerte = [
[ 0, 0, 0 ],
[ 63, 63, 63 ],
#...
];
Die eckigen Klammern um das äußere Array erzeugen eine Referenz auf ein Array und kein normales Array. Vielleicht ist es das, was Sie wollen, aber dann würden Sie das Ergebnis nicht einer Array-Variablen zuweisen. Statt dessen würden Sie die Referenz in einer Skalarvariablen unterbringen.
Ein Hash von Arrays ist eine verschachtelte Datenstruktur, in der ein Hash mit normalen Schlüsseln als Werte Referenzen auf Arrays erhält (siehe Abbildung 19.3). Sie könnten in einem Hash von Arrays zum Beispiel eine Liste von Personen und deren Kindern abspeichern. Die Schlüssel dieses Hash wären die Namen der Personen und die dazugehörigen Werte Listen der Namen der Kinder. Ein anderes Beispiel wäre ein Skript für ein Kino, das in einem Hash die Filme und deren Vorführungszeiten festhält.
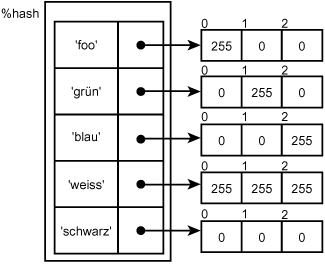
Abbildung 19.3: Hashes von Arrays
Um einen Hash von Arrays zu erzeugen, verwenden Sie für den äußeren Hash die Hash-Syntax, normale Strings als Schlüssel und anonyme Arrays als deren Werte (das folgende Beispiel enthält den Plan der sportlichen Aktivitäten in einem Sommerlager):
%plan = (
'Montag' => [ 'Bogenschiessen', 'Fussball', 'Tanz' ],
'Dienstag' => [ 'Korbflechten', 'Schwimmen', 'Kanufahren' ],
'Mittwoch' => [ 'Exkursion', 'Fussball', 'Tanz' ],
'Donnerstag' => [ 'Freizeit', 'Schwimmen', 'Kanufahren' ],
'Freitag' => [ 'Bogenschiessen', 'Fussball', 'Wandern' ],
);
Auch hier gilt es sorgfältig zwischen eckigen und runden Klammern zu unterscheiden.
Die inneren eckigen Klammern erzeugen die anonymen Arrays. Die äußeren runden
Klammern erzeugen eine Liste, die dann in einen Hash umgewandelt wird, wenn sie
der Variablen %plan zugewiesen wird. Mit geschweiften Klammern um die ganze Liste
würden Sie eine Referenz auf einen anonymen Hash erzeugen.
Beachten Sie, dass in einem Hash von Arrays nur die Werte Arrays sein können. Die Hash-Schlüssel müssen Strings sein. Genau genommen, geht Perl davon aus, dass es Strings sind, und wandelt gnadenlos alles andere (Zahlen und Referenzen) in Strings um. Achten Sie darauf, dass Sie bei verschachtelten Hashes für Ihre Schlüssel Strings verwenden.
Wie komplex hätten Sie es gerne? Hashes von Hashes ermöglichen es Ihnen, sehr komplexe Datenstrukturen zu erzeugen. In einem Hash von Hashes enthält der äußere Hash normale Schlüssel und Werte, in denen wiederum Hashes gespeichert sind (siehe Abbildung 19.4). Sie könnten dann mit speziellen Schlüsseln und »Unterschlüsseln« in den einzelnen Hashes suchen. In einem Hash von Hashes könnte man beispielsweise die Kinder einer Schulklasse und die Noten der Kinder in den einzelnen Fächern erfassen. Dabei bilden die Nachnamen der Kinder den Schlüssel, und die Werte wären untergeordnete Hashes mit Einträgen für den Vornamen, das Geburtsdatum und die Noten für jedes Fach.

Abbildung 19.4: Hashes von Hashes
Hashes von Hashes verwenden für den inneren Teil die Syntax anonymer Hashes und für den äußeren Teil die Syntax regulärer Listen:
%leute = (
'Jones' => {
'name' => 'Alison',
'alter' => 15,
'tier' => 'dog',
},
'Smith' => {
'name' => 'Tom',
'alter' => 18,
'tier' => 'fish',
},
);
Ich habe Ihnen in diesem Abschnitt drei einfache und häufig vorkommende Datenstrukturen vorgestellt: Arrays von Arrays, Hashes von Arrays und Hashes von Hashes. Sie können Arrays und Hashes jedoch fast beliebig mit Referenzen und anonymen Daten kombinieren, je nachdem, mit welchen Daten Sie arbeiten und wie sich die Daten am besten organisieren lassen. Sie können Ihre Daten auch noch tiefer verschachteln, als ich es hier getan habe. Denkbar wäre zum Beispiel auch ein Hash von einem Hash, in dem die Schlüssel Arrays und die Array-Elemente wiederum Hashes sind und so weiter. Es sind Ihnen hinsichtlich der Verschachtelungstiefe keine Grenzen gesetzt. Wenn es also die Situation erfordert, dann sollten Sie sich keine Beschränkungen auferlegen.
Die obigen Beispiele für verschachtelte Datenstrukturen mit anonymen Daten lassen sich überall dort gut anwenden, wo Sie bereits im voraus genau wissen, welche Daten die Strukturen enthalten werden. In der Praxis sieht es jedoch so aus, dass solche komplexeren Datenstrukturen meistens aus Daten aufgebaut sind, die aus einer Datei gelesen oder über die Tastatur eingegeben wurden.
In solchen Fällen kann es passieren, dass Sie sowohl mit anonymen Daten als auch mit Referenzen auf reguläre Variablen arbeiten. So lange die Referenzen dabei an der richtigen Stelle stehen, ist es egal, welchen Mechanismus Sie zum Aufbau Ihrer Datenstruktur verwenden. Angenommen Sie haben eine Datei, die die folgende Matrix von Zahlen enthält:
3 4 2 4 2 3
5 3 2 4 5 4
7 6 3 2 8 3
3 4 7 8 3 4
Sie wollen diese Datei in ein Array von Arrays einlesen, wobei jede Reihe ein eigenes Array bildet und das äußere Array die einzelnen Reihen speichert. Sie könnten dies mit einer Schleife wie folgt lösen:
while (<>) {
chomp;
push @matrix, [ split ];
}
Diese Schleife würde jede Zeile lesen, das Neue-Zeile-Zeichen mit chomp entfernen,
mit split die einzelnen Elemente voneinander trennen, mit Hilfe der eckigen
Klammern ein anonymes Array dieser Elemente erzeugen und zum Schluß die
Referenz auf dieses Array in das äußere Array schreiben (push).
Vielleicht denken Sie, dass dieses Beispiel besser lesbar wäre, wenn wir die Elemente zuerst in einer Liste aufsplitten und dann eine Referenz auf diese Liste speichern würden:
my @list = ();
while (<>) {
chomp;
@list = split;
push @matrix, \@list;
}
Aber dieses Beispiel hat einen großen Haken (eine Falle, in die viele Programmierer tappen, die dies zum ersten Mal versuchen). Für eine vorgegebene Eingabe wie die obige Matrix wird diese Schleife ein Array von Arrays erzeugen, das folgendermaßen aussieht:
3 4 7 8 3 4
3 4 7 8 3 4
3 4 7 8 3 4
3 4 7 8 3 4
Können Sie sich denken, warum? Das Problem hat mit dem Variablennamen zu tun,
auf den später die Referenz verweist. Bei jedem Durchlauf der Schleife ändert sich
zwar der Inhalt der Variablen @list, aber die Speicherposition bleibt die gleiche.
Jedesmal, wenn Sie eine Zeile lesen, legen Sie im äußeren Array eine Referenz auf die
gleiche Speicherposition ab. Das Array, das Sie am Ende erhalten, ist ein Array von
vier Referenzen, die alle auf genau die gleiche Speicherposition zeigen.
Eine Möglichkeit, diesen Fehler zu beheben - und er tritt häufig auf, also hören Sie gut zu -, besteht darin, eine Referenz auf eine Kopie der Array-Daten und nicht auf das Array selbst zu erzeugen. Auf diese Weise legen Sie im Speicher bei jedem Durchlauf der Schleife eine neue Position im Speicher an und erhalten Referenzen auf verschiedene Speicherplätze. Man erreicht dies, indem man einfach die eckigen Klammern für anonyme Arrays um die Array-Variable setzt:
my @list = ();
while (<>) {
chomp;
@list = split;
push @matrix, [ @list ];
}
Achten Sie darauf, dass Sie für anonyme Hashes analog vorgehen (also anonyme Hashes in ein Array von Hashes ablegen):
push @arrayvonhashes, { %hash };
Das Problem läßt sich aber auch damit lösen, dass Sie in der Schleife eine my-Variable
verwenden. Da die my-Variable bei jedem Schleifendurchlauf neu erzeugt wird, zeigt
die Referenz jedesmal im Speicher woanders hin:
while (<>) {
chomp;
my @list = split;
push @matrix, \@list ;
}
Verschachtelte Datenstrukturen zu erstellen ist eine Sache, auf die Elemente in verschachtelten Datenstrukturen zuzugreifen eine andere. Über Referenzen in Arrays, auf die wieder andere Referenzen weisen, auf ein bestimmtes Element zuzugreifen, ist schon eine unangenehme Aufgabe, besonders bei komplexen Strukturen. Doch zum Glück unterstützt Sie Perl dabei mit einer speziellen Syntax.
Angenommen Sie haben eine Matrix (Array von Arrays) von Zahlen, wie wir sie schon im obigen Abschnitt gesehen haben:
@zahlen = (
[ 3, 4, 2, 4, 2, 3 ],
[ 5, 3, 2, 4, 5, 4 ],
[ 7, 6, 3, 2, 8, 3 ],
[ 3, 4, 7, 8, 3, 4 ],
);
Nehmen wir jetzt an, Sie wollten auf das vierte Element in der dritten Reihe zugreifen. Mit Hilfe der Standardsyntax für den Arrayzugriff können Sie auf die dritte Reihe zugreifen:
$zahlen[2];
Das Ergebnis wäre jedoch nur eine Referenz und nicht die Daten, auf die die Referenz verweist (erinnern Sie sich, Sie erhalten die Daten, auf die eine Referenz weist, nur durch explizites Dereferenzieren). Um die Referenz zu dereferenzieren und ein echtes Element zu erhalten, könnten Sie folgendermaßen vorgehen:
$zahlen[2]->[3]; # liefert das vierte Element des Arrays, auf das die
# Referenz $zahlen[2] verweist
${ $zahlen[2] }[3]; # $zahlen[2] liefert Ihnen eine Referenz, die in dem
# Block dereferenziert wird
Beide Varianten sind möglich, doch keine ist besonders gut lesbar. Deshalb stellt Perl
Ihnen eine verkürzte Syntax für mehrdimensionale Arrays zur Verfügung, die den
Zugriff vereinfacht: Wenn Sie die standardmäßige Dereferenzierungssyntax mit dem
Pfeil verwenden, können Sie die ->-Zeichen fortlassen:
$zahlen[2][3];
Das ist wesentlich einfacher zu verstehen und entspricht dem Zugriff auf mehrdimensionalen Arrays in anderen Sprachen (wie C zum Beispiel).
Die Situation ist jedoch eine andere, wenn Sie anstatt eines echten Arrays in @zahlen
nur eine Referenz auf ein Array von Arrays hätten. Dann wären nämlich zwei
Referenzen zu dereferenzieren, und Sie würden folgende Syntax verwenden (hier ist
@zahlenref die Referenz auf das Array von Arrays):
$zahlenref->[2][2];
Bei verschachtelten Hashes von Arrays und Hashes von Hashes verhält es sich analog, mit geschweiften Klammern für die Hash-Schlüssel und eckigen Klammern für die Array-Indizes:
$hash{joe}[5]; # Zugriff auf das sechste Element eines Arrays
# des Hash %hash über den Schlüssel 'joe'
$hashref->{joe}[5]; # das gleiche, wenn $hashref eine Referenz enthält
$hash{Jones}{alter}; # Wert alter für den Jones-Datensatz in %hash
$hashref->{Jones}{alter}; # das gleiche, $hashref ist Referenz
Wenn Sie all diese verschachtelten Indizes und Schlüssel zu sehr verwirren, können Sie statt dessen von der Referenz auf das interne Array oder Hash, das Sie gerade interessiert, eine temporäre Kopie erzeugen und dann diese Referenz auf normalem Weg dereferenzieren:
my $tempref = $zahlen[0]; # Referenz auf die erste Reihe von Zahlen
print $$tempref[5]; # gibt fünftes Element aus
# das gleiche wie $zahlen[0][5]
Sie sind nur an einem Teilbereich eines verschachtelten Arrays interessiert? Normalerweise würden Sie dafür die übliche Syntax verwenden, mit den Referenzen an den entsprechenden Stellen. Des weiteren sind Sie in diesem Fall auf die Blockdereferenzierung angewiesen und am Ende erhalten Sie einen ziemlich häßlichen Ausdruck wie zum Beispiel:
@elemente = @{ $zahlen[1] }[2..5]; # extrahiert die Elemente 2 bis 5
# im zweiten Array aus @zahlen):
Da diese Notation sehr schnell ziemlich unangenehm werden kann, ist es meist leichter, die Referenzen in temporären Variablen abzulegen und über diese die Teilbereiche zu entnehmen. Oder Sie setzen Schleifen auf, in denen die Elemente einzeln aus dem verschachtelten Array herausgezogen werden. Wenn Sie vertikale Bereiche herauslösen wollen (je ein Element aus verschiedenen der verschachtelten »Reihen«) oder rechteckige Bereiche (einige Elemente horizontal und mehrere Elemente vertikal), dann müssen Sie dazu eine Schleife verwenden.
Verschachtelte Datenstrukturen eignen sich bestens zum Verwahren komplexer Datensätze und ermöglichen es, diese Daten auf verschiedene Art und Weise zu manipulieren. In diesem Abschnitt untersuchen wir eine Datenbank, in der Künstler aufgeführt werden. Neben den Namen der Künstler enthält die Datenbank Informationen zu den einzelnen Künstlern und ihren Werken. Um Platz zu sparen, halte ich das Beispiel kurz und beschränke mich darauf,
Die Daten, die wir in diesem Beispiel betrachten, umfassen den Vor- und Nachnamen der Künstler, ihr Geburts- und Todesjahr sowie eine Liste der Titel ihrer Werke. Die Künstlerdaten sind in einer externen Datei gespeichert, die pro Künstler zwei Zeilen aufweist:
Monet,Claude,1840,1926
Herbst in Argenteuil:Pappeln:Camille:Wasserlilien
Die erste Zeile besteht aus den persönlichen Daten des Künstlers, die jeweils durch
Kommata getrennt sind, die zweite Zeile enthält die Werke des Künstlers, getrennt
durch Doppelpunkte. Die Datendatei, die ich kuenstler.txt genannt habe, enthält
eine Reihe von Künstlern im gleichen Format.
Die Struktur, in die wir diese Informationen lesen, ist ein Hash von Hashes mit einem
verschachtelten Array. Der oberste Hash verwendet als Schlüssel den Nachnamen des
Künstlers. Die weiteren Künstlerdaten sind in einem verschachtelten Hash mit den
Schlüsseln FN, BD, DD und works. Der Wert für den Schlüssel works ist wiederum ein
Array, in dem die einzelnen Titel aufgeführt sind.
Listing 19.1 enthält den Code für dieses einfache Beispiel. Bevor Sie dazu übergehen,
die Analyse dieses Codes zu lesen, studieren Sie die Zeilen in der while-Schleife, vor
allem der Subroutine &read_input() (Zeilen 21 bis 35) und der Dereferenzierungen in
der Subroutine &process() (Zeilen 53 und 55).
Listing 19.1: Das Skript kuenstler.pl
1: #!/usr/bin/perl -w
2: use strict;
3:
4: my $artdb = "kuenstler.txt"; # Name der Künstlerdatenbank
5: my %artists = (); # Hash der Künstler, Nachname
# als Schlüssel
6:
7: &read_input();
8: &process();
9:
10: sub read_input {
11: my $in = ''; # temp. Eingabezeile
12: my ($fn,$ln,$bd,$dd); # Nachname, Vorname
13: # Geburtsjahr, Todesjahr
14: my %artist = (); # temp. Künstler-Hash
15:
16: open(FILE, $artdb) or
die "Datenbank ($artdb) konnte nicht geöffnet werden: $!\n";
17:
18: while () {
19: # Name und Daten in erster Zeile
20: chomp($in = <FILE>);
21: if ($in) {
22: ($ln,$fn,$bd,$dd) = split(',',$in);
23: $artist{FN} = $fn;
24: $artist{BD} = $bd;
25: $artist{DD} = $dd;
26:
27: chomp($in = <FILE>); # Liste der Werke in zweiter Zeile
28: if ($in) {
29: my @works = split(':',$in);
30: $artist{works} = \@works;
31: } else { print "no works";}
32:
33: # die Referenz auf das artist-Hash in das äußere
34: # artists-Hash eintragen
35: $artists{$ln} = { %artist };
36:
37: } else { last; } # Ende von DB
38: }
39:
40: }
41:
42: sub process {
43: my $input = '';
44: my $matched = 0;
45:
46: print "Geben Sie einen Künstlernamen ein: ";
47: chomp($input = <>);
48:
49: foreach (keys %artists) {
50: if (/$input/i and !$matched) {
51: $matched = 1;
52: my $ref = $artists{$_};
53: print "$_, $ref->{FN} $ref->{BD}-$ref->{DD}\n";
54: my $work = '';
55: foreach $work (@{$ref->{works}}) {
56: print " $work\n";
57: }
58: }
59: }
60: if (!$matched) {
61: print "Der Künstler $input wurde nicht gefunden.\n";
62: }
63: }
Vielleicht ist Ihnen aufgefallen, dass ich in diesem Beispiel genau das Gegenteil von dem gemacht habe, was ich zuvor gepredigt habe: Anstatt alle Variablen lokal zu halten, verwende ich eine globale Variable für die globale Künstlerdatenbank. Wie Sie Ihre Daten und Variablen organisieren, bleibt Ihnen überlassen. Ich verwende in diesem Fall eine globale Variable, weil das Dereferenzieren ohnehin schon kompliziert genug ist und ich daher nicht noch eine weitere Ebene hinzufügen möchte.
Was Ihnen in diesem Beispiel vielleicht auch noch seltsam erscheinen mag, ist der hartcodierte Name der Künstlerdatenbank. Ich habe den Namen der Datei bewußt in den Code des Skripts mit aufgenommen, statt ihn über die Befehlszeile eingeben zu lassen. Aber auch dies ist eine Frage des Programmierstils und wie das Skript verwendet wird. Beide Wege sind gangbar (beachten Sie, dass ich den Dateinamen der Künstlerdatenbank ganz oben im Skript gesetzt habe, so dass er bei Bedarf schnell geändert werden kann).
Betrachten wir zuerst die Subroutine &read_input(), die die Künstlerdatenbank
einliest und unsere verschachtelte Datenstruktur mit Daten füllt. Ich bin dabei so
vorgegangen, dass ich einen temporären Hash für den aktuellen Künstler einrichte,
diesen Hash mit Daten fülle und dann den temporären Hash über eine Referenz in
den äußeren Hash eintrage.
Wir beginnen in Zeile 18 mit einer Schleife, die die Datenbankdatei der Künstler in Schritten von je zwei Zeilen einliest. Die Schleife wird verlassen, wenn es keine weiteren Daten mehr gibt (Test in Zeile 21). Zuerst wird die erste Zeile der Daten eingelesen, die den Namen des Künstlers sowie seine persönlichen Daten enthält:
Monet,Claude,1840,1926
Zeile 22 zerlegt diese Daten in ihre Einzelbestandteile, und die Zeilen 23 und 25 legen
diese Daten dann in einem temporären Hash ab (namens %artist, der jedoch nicht
mit dem äußeren Hash %artists verwechselt werden sollte).
Zeile 27 liest die jeweils zweite Zeile der Künstlerdaten ein, das heißt die einzelnen Werke:
Herbst in Argenteuil:Pappeln:Camille:Wasserlilien
In Zeile 29 teilen wir diese Zeile auf der Basis des Trennzeichens »:« in Listenelemente
auf und speichern diese Liste in dem temporären Array @works. In Zeile 30 fügen wir
eine Referenz auf dieses Array in unseren temporären Hash %artist mit dem
Schlüssel »works« ein. Beachten Sie, dass wir bei jedem Durchlauf der while-Schleife
einen neuen temporären @works-Array (deklariert mit my) erhalten, so dass wir das
Problem, jedesmal die gleiche Speicherposition zu referenzieren, umgehen.
Nachdem wir auf diese Weise die Daten des Künstlers eingelesen haben, können wir
diesen Datensatz endlich in den äußeren Künstler-Hash eintragen, wobei uns der
Nachname des Künstlers als Schlüssel dient. Und genau das geschieht in Zeile 35.
Beachten Sie hierbei, dass wir, da bei jedem Schleifendurchlauf der gleiche Hash
%artist verwendet wird, einen anonymen Hash-Konstruktor und eine Kopie des
Hash %artist verwenden, um sicherzustellen, dass die Referenz jedesmal auf eine
andere Speicherposition weist.
Die Subroutine &read_input() legt die Daten in einem verschachtelten Hash ab, die
Subroutine &process() holt die Daten wieder heraus. Dazu bedienen wir uns eines
einfachen Algorithmus, um nach dem Nachnamen des Künstlers zu suchen und den
gefundenen Datensatz auszugeben. Die Ausgabe dieser Subroutine sieht wie folgt aus:
Geben Sie einen Künstlernamen ein: Monet
Monet, Claude 1840-1926
Herbst in Argenteuil
Pappeln
Camille
Wasserlilien
Den wichtigsten Teil dieser Subroutine bilden die Zeilen 52 bis 56, in denen die
Referenzen dereferenziert werden, um an die benötigten Daten zu gelangen. Lassen
Sie uns aber weiter oben in Zeile 49 mit der foreach-Schleife beginnen. Da wir keine
eigentliche Schleifenvariable haben, speichert Perl die Schlüssel (die Nachnamen der
jeweiligen Künstler) in der Variablen $_.
Zeile 50 enthält den eigentlichen Test: Wir führen mit der Eingabe und dem aktuellen
Schlüssel einen Mustervergleich durch, um festzustellen, ob es eine Übereinstimmung
gibt. Und da wir in diesem Beispiel nur an der ersten Übereinstimmung interessiert
sind, verfolgen wir außerdem die Variable $matched, um zu sehen, ob bereits eine
Übereinstimmung gefunden wurde.
Angenommen es wurde ein übereinstimmender Datensatz gefunden, dann gehen wir
weiter zu Zeile 52. Hier erzeugen wir eine temporäre Variable, die die Referenz auf
den Datensatz des Künstlers aufnimmt - dies ist, wie in unserem stats-Beispiel, nicht
unbedingt notwendig, erleichtert aber die Verwaltung der Referenzen. Da $_ den
übereinstimmenden Schlüssel enthält, können wir die Referenz in diesem Falle mit
einer einfachen Hash-Suche ermitteln.
Haben wir erst einmal die Referenz, können wir sie dereferenzieren, um Zugriff auf
den Inhalt des Hash zu erhalten. In Zeile 53 geben wir die persönlichen Daten aus:
den Nachnamen ($_), den Vornamen (der Wert des Schlüssels FN im Hash), das
Geburtsjahr (BD) und das Todesjahr (DD).
Die Zeilen 54 bis 56 dienen dazu, die Werke des Künstlers auf jeweils einer Zeile
auszugeben. Merkwürdig ist allein die Referenz in der foreach-Schleife. Betrachten
wir diese einmal näher:
@{$ref->{works}}
Zur Erinnerung: In $ref befindet sich eine Referenz auf einen Hash. Der Ausdruck
$ref->{works} dereferenziert diese Referenz und liefert den Wert zurück, der durch
den Schlüssel works gegeben ist. Dieser Wert ist wiederum eine Referenz, diesmal
jedoch eine Referenz auf ein Array. Um diese Referenz zu dereferenzieren und ein
tatsächliches Array zu erhalten, das man mit der foreach-Schleife durchlaufen kann,
bedarf es der Blocksyntax zum Dereferenzieren: @{}.
Referenzen zu verstehen und herauszufinden, wie man an die tatsächlichen Daten
herankommt, ist nicht immer ganz einfach. Meist hilft es, wenn man von außen nach
innen vorgeht, wo nötig, Blöcke verwendet und wenn hilfreich, temporäre Variablen
einsetzt. Auch die Analyse der Referenzausdrücke im Perl-Debugger oder mit print-
Anweisungen kann helfen, die richtigen Dereferenzierungen zu erzeugen.
Die Erzeugung und Verwendung von Referenzen ist sicherlich einer der komplexeren Aspekte von Perl (vermutlich nur von der objektorientierten Programmierung übertroffen, die wir morgen besprechen wollen). Die heutige Lektion hat Sie in die Grundlagen der Referenzen eingeführt und Ihnen die wichtigsten Einsatzbereiche aufgezeigt. Wie aber bei den meisten Themen in Perl gibt es auch im Zusammenhang mit Referenzen viele Bereiche, die ich nicht angesprochen habe, einschließlich der symbolischen Referenzen (eine gänzlich andere Form von Referenz) sowie der Referenzen auf Subroutinen, Typeglobs und Datei-Handles.
Weitere Informationen zu Referenzen finden Sie in der perlref-Manpage. Wenn Sie intensiver mit verschachtelten Datenstrukturen arbeiten, finden Sie weitere Details und Beispiele in perldsc (Kochbuch der Datenstrukturen) und perllol (Liste der Listen).
Müssen Sie mehrere skalare Referenzen auf einmal erstellen? So geht es ganz leicht:
@listevonrefs = \($ding1, $ding2, $ding3, $ding4);
Auf diese Weise erhalten Sie in @listevonrefs eine Liste von Referenzen. Es ist eine
Kurzform von :
@listevonrefs = (\$ding1, \$ding2, \$ding3, \$ding4);
Wie ich zu Beginn dieser Lektion schon am Rande bemerkt habe, kennt Perl eigentlich zwei Arten von Referenzen: harte Referenzen und symbolische Referenzen. Die von mir in dieser Lektion durchgehend verwendeten Referenzen waren harte Referenzen. Harte Referenzen sind eigentlich skalare Daten, die wie Skalare manipuliert werden können und die dereferenziert werden, um auf die referenzierten Daten zuzugreifen.
Symbolische Referenzen sind anders: Eine symbolische Referenz ist einfach ein String. Wenn Sie versuchen, diesen String zu dereferenzieren, wird der String als der Name einer Variablen interpretiert, und falls diese Variable existiert, erhalten Sie den Wert dieser Variablen. Sehen Sie dazu folgendes Beispiel:
$foo = 1; # Variable $foo enthält Wert 1
$symref = "foo"; # String
$$symref = "Ich bin eine Variable"; # setzt die Variable $foo
print "symbolische Referenz: $symref\n"; # Ergebnis ist "foo"
print "Foo: $foo\n"; # Ergebnis ist "Ich bin eine Variable"
print "dereferenziert: $$symref\n"; # gibt $foo aus,
# Ergebnis ist "Ich bin eine Variable"
Wie Sie sehen können, lassen sich symbolische Referenzen wie richtige Referenzen
verwenden, es sind jedoch nur Strings, die Variablen benennen. Der Unterschied ist
sehr fein und verwirrend, besonders wenn Sie harte und symbolische Referenzen
kombinieren. So könnten Sie aus Versehen einen String dereferenzieren, wenn Sie
eigentlich vorhatten, einen Skalar zu dereferenzieren, ein Fehler, der sich nur schwer
beim Debuggen aufdekken läßt. Aus diesem Grund verfügt Perl über ein strict-
Pragma, mit dem Sie die Verwendung von Referenzen auf harte Referenzen
beschränken können.
use strict 'refs';
Wenn Sie dieses Pragma ganz oben in Ihr Skript mit aufnehmen, können Sie
verhindern, dass symbolische Referenzen verwendet werden. Den gleichen Effekt
erzielen Sie aber auch, wenn Sie oben in Ihrem Skript use strict allein verwenden.
Zwei Arten von Referenzen, die ich im Hauptteil dieser Lektion nicht besprochen habe, sind die Referenzen auf Typeglobs, die wiederum Referenzen auf Datei-Handles ermöglichen. Ein Typeglob ist, wie ich weiter vorn in diesem Buch kurz bemerkt habe, eine Möglichkeit, auf mehrere Typen von Variablen, die den gleichen Namen teilen (der in der Symboltabelle eingetragen ist), gleichzeitig Bezug zu nehmen. Typeglobs werden heutzutage in Perl nicht mehr so oft verwendet wie früher, als es noch keine Referenzen gab und man die Typeglobs dazu nutzte, Verweise auf Listen an Subroutinen zu übergeben. Typeglobs stellen aber auch einen Weg dar, um Referenzen auf Datei-Handles zu erzeugen, und geben uns damit eine Möglichkeit an die Hand, bei Bedarf Datei-Handles in und aus Subroutinen zu übergeben oder lokale Datei-Handles zu erzeugen.
Um eine Referenz auf einen Datei-Handle zu erzeugen, verwenden Sie einen
Typeglob mit dem Namen des Datei-Handles und dem Backslash-Operator \:
$fh = \*MEINEDATEI;
Für den lokalen Datei-Handle verwenden Sie den Operator local (nicht my) und ein
Datei-Handle-Typeglob:
local *MEINEDATEI;
Weitere Informationen finden Sie in der perldata-Manpage (im Abschnitt zu Typeglobs und Datei-Handles).
Noch nützlicher als Referenzen auf Datei-Handles sind Referenzen auf Subroutinen. Da die Definitionen von Subroutinen wie Arrays oder Hashes im Speicher abgelegt sind, können Sie - wie bei anderen Daten auch - Referenzen auf Subroutinen erzeugen. Wenn Sie eine Referenz auf eine Subroutine dereferenzieren, rufen Sie die Subroutine auf.
Mit Referenzen auf Subroutinen können Sie die Definition einer Subroutine während der Ausführung ändern oder je nach Situation zwischen verschiedenen Subroutinen wählen. Referenzen auf Subroutinen öffnen zudem das Tor zu fortgeschrittenen Techniken in Perl, wie zum Beispiel die objektorientierte Programmierung und Closures (anonyme Subroutinen, deren lokale Variablen sich danach richten, in welchem Gültigkeitsbereich die Subroutine definiert wurde - auch wenn sie später in einem anderen Gültigkeitsbereich aufgerufen wurden).
Um eine Referenz auf eine Subroutine zu erzeugen, verwenden Sie den Backslash- Operator mit dem Namen einer bereits definierten Subroutine:
$subref = \&meinesub;
Sie können auch Referenzen auf anonyme Subroutinen erzeugen, indem Sie einfach den Namen der Subroutine bei der Definition fortlassen:
$subref = sub { reverse @_;};
Zum Dereferenzieren verwenden Sie die bekannte Referenzsyntax oder einen Block. Wenn Sie eine Subroutine dereferenzieren, rufen Sie sie auf; deshalb sollten Sie nicht vergessen, die Argumente mit einzuschließen:
@ergebnis = &$subref(1..10);
Weitere Details zu Referenzen auf Subroutinen und zu Closures finden Sie in der perlref-Manpage.
Der letzte große Teilbereich von Perl, der in diesem Buch noch zur Besprechung anstand, betraf die Referenzen. Mit der heutigen Lektion haben Sie eine gute Einführung in die Erzeugung und Verwendung von Referenzen in verschiedenen Kontexten erhalten.
Referenzen sind so etwas wie skalare Daten, die auf andere Daten (einen anderen Skalar, ein Array, einen Hash oder eine Subroutine) verweisen. Da Referenzen Skalare sind, können Sie sie an Subroutinen übergeben, in Variablen speichern, sie als String oder als Zahl behandeln, auf ihren Wahrheitswert testen oder sie in ein Array aufnehmen. Sie können Referenzen auf zwei Arten erzeugen:
\ mit einer Variablen.
Um Zugriff auf das zu erhalten, worauf die Referenz verweist, müssen Sie die Referenz dereferenzieren. Eine Referenz läßt sich auf drei Arten dereferenzieren:
$$ref, @$ref oder $$ref[0].
@{$ref[0]}.
$ref->[0]
oder $ref->{key}. Bei verschachtelten Arrays und Hashes können Sie mehrere
Indizes angeben, ohne dazwischen Pfeile setzen zu müssen ($ref->[0][4] oder
$ref[0]{key}).
Neben den Grundtechniken zur Erzeugung und Verwendung von Referenzen habe ich
Ihnen zwei der häufigsten Einsatzbereiche für Referenzen vorgestellt: als Argumente
für Subroutinen (um die Struktur von Arrays und Hashes bei der Übergabe an
Subroutinen zu erhalten) und zur Erzeugung von verschachtelten Datenstrukturen wie
Arrays von Arrays und Arrays von Hashes. Schließlich haben Sie die ref-Funktion
kennengelernt, die einen String zurückliefert, der Ihnen anzeigt, welche Art Daten die
Referenz enthält.
Meinen Glückwunsch! Heute haben Sie die wirklich harte Arbeit mit diesem Buch abgeschlossen. Morgen untersuchen wir noch einige weitere Perl-Konzepte, die bisher noch nicht zur Sprache gekommen sind, und in Kapitel 21 beenden wir das Buch mit einigen Beispielen, die das bisher Gelernte praktisch umsetzen.
Frage:
Kann man Referenzen auf Referenzen erzeugen?
Antwort:
Aber selbstverständlich! Alles, was Sie dazu tun müssen, ist den Backslash-
Operator zu verwenden, um die Speicherposition der Referenz zu erhalten.
Denken Sie jedoch daran, dass Sie Referenzen auf Referenzen zweimal
dereferenzieren müssen, um an die eigentlichen Daten zu gelangen.
Frage:
Ich versuche ein Array von Arrays mit Daten aus einer Datei zu füllen. Ich lese die
Daten in ein einfaches Array und füge dieses Array dann in ein äußeres Array ein.
Aber am Ende enthält das ganze Array nichts außer den zuletzt hinzugefügten
Werten. Was mache ich falsch?
Antwort:
Das klingt, als wenn Sie ungefähr folgendes versuchen:
while (<>) {
@input = split $_;
@grossesarray = \@input;
}
Das Problem hierbei ist, dass alle Referenz auf
@input, die Sie erzeugen, auf die gleiche Speicherposition zeigen. Der Inhalt von@inputändert sich also bei jedem Schleifendurchlauf, die Position jedoch bleibt die gleiche. Alle Referenzen zeigen deshalb auf die gleiche Stelle und haben als Wert die zuletzt dort abgelegten Dinge. Um das Problem zu lösen, können Sie
input-Variable als my-Variable in der Schleife deklarieren.
Damit erzeugen Sie jedesmal auch eine neue Speicherposition.
@input einen anonymen Array-Konstruktor verwenden
(das heißt [ @input ]). Damit erzeugen Sie eine Referenz auf eine Kopie
des Inhalts der Eingabe und somit auch jedesmal eine neue
Speicherposition.
Frage:
Ich habe ein Array von Arrays erzeugt und mit der Anweisung print
"@meinarrary\n"; ausgegeben. Aber erhalten habe ich nur:
ARRAY(0x807f048) ARRAY(0x808a06c) ARRAY(0x808a0cc)
Antwort:
Bei Arrays von Arrays ist eine Variableninterpolation nicht möglich. Ihr print-
Befehl gibt nur die obere Ebene des Arrays aus - was im wesentlichen drei
Referenzen sind. Die ARRAY(...)-Formulierungen sind lediglich die
druckbaren Stringdarstellungen dieser Referenzen. Um ein verschachteltes
Array (oder eine beliebige andere verschachtelte Datenstruktur) auszugeben,
müssen Sie eine oder mehrere foreach-Schleifen verwenden und die
Referenzen selbst dereferenzieren. Hier ein Beispiel dafür, wie sich dies
realisieren ließe:
foreach (@meinarray) {
print "( @$_ )\n";
}
Der Workshop enthält Quizfragen, die Ihnen helfen sollen, Ihr Wissen zu festigen, und Übungen, die Sie anregen sollen, das eben Gelernte umzusetzen und eigene Erfahrungen zu sammeln. Versuchen Sie, das Quiz und die Übungen zu beantworten und zu verstehen, bevor Sie zur Lektion des nächsten Tages übergehen.
$ref eine Referenz, die entweder auf einen Skalar,
ein Array, einen Hash oder eine verschachtelte Datenstruktur verweist. Was ist
das Ergebnis der folgenden Dereferenzierungen? (Gehen Sie davon aus, dass die
Referenz auf die für jedes Beispiel geeignetsten Daten zeigt.)
$$ref;
$$ref[0];
$ref->[0];
@$ref;
$#$ref;
$ref->[0][5];
@{$ref->{key}};
%hash = {
key => [ 1.. 10 ],
key2 => [ 100 ..110],
};
$ref = \%hash;
foreach (keys %$ref) {
print "$$ref{$_}\n";
}
$listref gespeichert ist:
[ 3, 4, 2, 4, 2, 3 ]
[ 5, 3, 2, 4, 5, 4 ]
[ 7, 6, 3, 2, 8, 3 ]
[ 3, 4, 7, 8, 3, 4 ]
&rect()) mit dem Startpunkt 0,0 aufrufen, um ein
Rechteck von 3x3 Elementen auszuschneiden
&rect($listref,0,0,3,3);
3 4 2
5 3 2
7 6 3
Geben Sie die Koordination Ihrer Wahl ein (z.B. A4): C4
Daneben! Neuer Versuch.
A B C D E
---------
1| 0 0 0 0 0
2| 0 0 0 0 0
3| 0 0 0 0 0
4| 0 0 X 0 0
5| 0 0 0 0 0
Geben Sie die Koordination Ihrer Wahl ein (z.B. A4): B3
Daneben! Neuer Versuch.
A B C D E
---------
1| 0 0 0 0 0
2| 0 0 0 0 0
3| 0 X 0 0 0
4| 0 0 X 0 0
5| 0 0 0 0 0
Geben Sie die Koordination Ihrer Wahl ein (z.B. A4): E1
Glückwunsch! Sie haben das Schiff versenkt!
Hier die Antworten auf die Workshop-Fragen aus dem vorigen Abschnitt.
$ref = \@array;
$ref = [ 1 ..100 ];
$ding = $$ref[0];
$ding = $ref->[0];
SCALAR, ARRAY, HASH und so weiter), und die Speicherposition der
Daten (als Hexadezimalzahl).
$ref eine Referenz auf einen Skalar ist, liefert der
Ausdruck einen Skalar zurück.
$ref eine Referenz auf ein Array ist, liefert der
Ausdruck das erste Element dieses Arrays zurück.
$ref eine Referenz auf ein Array ist, liefert der
Ausdruck den Inhalt des Arrays (oder in einem skalaren Kontext die Anzahl
der Elemente) zurück.
$ref eine Referenz auf ein Array ist, liefert der
Ausdruck den letzten Index des Arrays zurück.
$ref eine Referenz auf ein mehrdimensionales Array
ist, liefert der Ausdruck das sechste Element in der ersten Reihe zurück.
$ref eine Referenz auf einen Hash von Arrays ist,
liefert der Ausdruck den Inhalt des Arrays zurück, das den Schlüssels key hat.
sub reverseall {
my $listref;
foreach $listref (@_) {
if (ref($listref) eq 'ARRAY') {
my @templist = reverse @$listref;
$listref = \@templist;
} else {
print "$listref ist keine Liste\n";
}
}
return @_;
}
{}) erzeugen eine
Referenz auf einen Hash und keinen normalen Hash. Dafür müssen Sie wie folgt
runde Klammern verwenden:
%hash = (
key => [ 1.. 10 ],
key2 => [ 100 ..110],
);
print-Anweisung. Diese Anweisung
dereferenziert erfolgreich $ref und gibt die Werte im Hash aus. Da die Werte im
Hash aber wiederum Referenzen sind, wird die Ausgabe folgendermaßen
aussehen:
ARRAY(0x807f670)
ARRAY(0x807f7a8)
print "@{ $$ref{$_} }\n";
my $arrayref = $$ref{$_};
print "@$arrayref\n";
sub rect {
my $ref = shift;
my ($c1,$c2,$width,$height) = @_;
my @finalarray = ();
my @slice = ();
my $rowref;
for (; $height > 0; $height--) { # Reihen
my $c = $c2;
if ($$ref[$c1]) { # fängt zu große Höhen ab
$rowref = $$ref[$c1];
} else {next;}
for (my $w = $width; $w > 0; $w--) { # Spalten
if ($$rowref[$c]) { # fängt zu breite Breiten ab
push @slice, $$rowref[$c];
$c++;
}
}
push @finalarray, [ @slice ];
@slice = (); # setzt den Bereich für das nächste Mal zurück
$c1++;
}
return \@finalarray;
}
#!/usr/bin/perl -w
use strict;
my @board = (
[ 0, 0, 0, 0, 0 ],
[ 0, 0, 0, 0, 0 ],
[ 0, 0, 0, 0, 0 ],
[ 0, 0, 0, 0, 0 ],
[ 0, 0, 0, 0, 0 ],
);
my $hit = 0;
my @coords = &init();
while () {
&print_board();
my @choice = &get_coords();
if (&compare_coords(@choice,@coords)) {
print "Glückwunsch! Sie haben das Schiff versenkt!\n";
last;
} else {
print "Daneben! Neuer Versuch.\n";
&mark_board(@choice);
}
}
sub init {
srand;
my $num1 = int(rand 5);
my $num2 = int(rand 5);
return ($num1, $num2);
}
sub print_board {
$, = ' ';
print "\n A B C D E \n";
print " --------- \n";
my $i = 1;
foreach (@board) {
print "$i| @$_ \n";
$i++;
}
print "\n";
}
sub get_coords {
my ($c1, $c2);
my $coords;
while () {
print "Geben Sie die Koordinaten Ihrer Wahl ein (z.B. A4): ";
chomp($coords = <>);
($c1,$c2) = split('',$coords);
$c1 = uc $c1;
if ($c1 !~ /[ABCDE]/i) {
print "Ungültige Buchstaben-Koordinate. A - E, bitte.\n";
next;
} elsif ($c2 !~ /[1-5]/) {
print "Ungültige Zahlen-Koordinate. 1- 5 bitte.\n";
next;
} else { last; }
}
($c1 eq 'A') and $c1 = 0;
($c1 eq 'B') and $c1 = 1;
($c1 eq 'C') and $c1 = 2;
($c1 eq 'D') and $c1 = 3;
($c1 eq 'E') and $c1 = 4;
$c2--;
return ($c1, $c2);
}
sub compare_coords {
my ($c1,$c2,$d1,$d2) = @_;
if ($c1 == $d1 and $c2 == $d2) { return 1; }
else { return 0; }
}
sub mark_board {
my ($c2,$c1) = @_;
$board[$c1][$c2] = 'X';
}